直播场景TCP秒开优化
当前公司直播项目拨测的秒开指标远未达到预期,经过数据对比和分析,发现在拨测节点 Player 与边缘节点之间的 Lastmile 网络质量上存在比较大的问题,由于目前 Player 的拉流协议使用的是基于 TCP 的标准协议(HTTP-FLV),并且 Player 位于第三方平台,不受控制,所以重点只能通过单边优化公司边缘节点与 Player 之间的 TCP 连接参数,尽量加快 TCP 的建连和数据下发的速度。
现状
公司使用静态节点和动态节点作为边缘以节省成本,且多种业务集中进行混布,其中动态节点质量较差,但成本较低,也是导致问题的关键所在,在对Linux 内核的升级和参数调整操作上一定要慎重。
当前动态节点版本及相关配置:
- 内核版本:5.4.119-19-0006
- 见下面章节
优化验证
环境准备
TC 配置
首先安装 tc 工具,系统默认不安装:
sudo apt update
sudo apt install -y iproute2
tc --version
启动配置网损:
比如配置 lo 网卡 50~150ms 左右的延迟,且包含 0~15% 的一个随机丢包,配置如下:
$ sudo su
$ tc qdisc add dev lo root netem delay 50ms 25ms distribution normal loss random 0% 15%
# 查看配置是否生效
$ tc qdisc show dev lo
qdisc netem 8002: root refcnt 2 limit 1000 delay 50ms 25ms
验证:
$ ping 127.0.0.1 -i 0.2
PING 127.0.0.1 (127.0.0.1) 56(84) bytes of data.
64 bytes from 127.0.0.1: icmp_seq=1 ttl=64 time=102 ms
64 bytes from 127.0.0.1: icmp_seq=2 ttl=64 time=115 ms
64 bytes from 127.0.0.1: icmp_seq=3 ttl=64 time=175 ms
64 bytes from 127.0.0.1: icmp_seq=4 ttl=64 time=80.4 ms
--- 127.0.0.1 ping statistics ---
21 packets transmitted, 20 received, 4.7619% packet loss, time 4016ms
rtt min/avg/max/mdev = 48.201/113.013/207.390/42.338 ms, pipe 2
恢复:
# 删除配置
$ tc qdisc del dev lo root
注意: 不要无脑 copy 别人的 tc 配置命令,使用了 channge 而非 add,导致 Error: Qdisc not found. To create specify NLM_F_CREATE flag. 报错,还以为内核缺少 sch_netem 模块,差点重新安装完整内核。
可以通过命令:modinfo sch_netem 查看系统是否已经安装有 sche_netem 模块,如果没有就会报错,有的话会有模块信息输出:
filename: /lib/modules/6.8.0-51-generic/kernel/net/sched/sch_netem.ko.zst
description: Network characteristics emulator qdisc
license: GPL
srcversion: 7631AD62974660130A36DCA
depends:
retpoline: Y
intree: Y
name: sch_netem
vermagic: 6.8.0-51-generic SMP preempt mod_unload modversions
sig_id: PKCS#7
signer: Build time autogenerated kernel key
sig_key: 29:0D:80:5A:E0:B3:D6:D4:D4:D3:D0:EF:AB:48:F3:DB:73:58:2F:63
sig_hashalgo: sha512
signature: 03:A4:1E:0E:CA:01:0F:58:3E:93:93:A7:25:97:FC:82:3E:4F:60:CA:
00:84:75:DF:A3:20:F7:1B:92:9D:B1:58:6D:E2:47:92:84:83:00:FD:
...
NetPerf
- 启动 netserver
启动 netserver, netserver 与 netperf 是同一套 Tools,只是 server 测启动命令:
$ ~$ netserver -h
Usage: netserver [options]
Options:
-h Display this text
-D Do not daemonize
-d Increase debugging output
-f Do not spawn chilren for each test, run serially
-L name,family Use name to pick listen address and family for family
-N No debugging output, even if netperf asks
-p portnum Listen for connect requests on portnum.
-4 Do IPv4
-6 Do IPv6
-v verbosity Specify the verbosity level
-V Display version information and exit
-Z passphrase Expect passphrase as the first thing received
# 启动命令
$ ~$ sudo netserver -p 1234 -D -4
check_if_inetd: enter
setup_listens: enter
create_listens: called with host '0.0.0.0' port '1234' family AF_INET(2)
getaddrinfo returned the following for host '0.0.0.0' port '1234' family AF_INET
cannonical name: '(nil)'
flags: 1 family: AF_INET: socktype: SOCK_STREAM protocol IPPROTO_TCP addrlen 16
sa_family: AF_INET sadata: 4 210 0 0 0 0 0 0 0 0 0 0 0 0 0 0
Starting netserver with host 'IN(6)ADDR_ANY' port '1234' and family AF_INET
accept_connections: enter
set_fdset: enter list 0x5f3130ac4740 fd_set 0x7fff92fb9450
setting 3 in fdset
使 netserver 监听在 1234 端口上,并指定 IPv4 协议,-D 表示不在后台运行。
- 启动 Client
netperf -H 127.0.0.1 -p 1234 -l 10 -t TCP_CRR -- -r 100,3000000
参数说明:
-H: 指定 server 的 IP 地址
-p: 指定 server 的 port
-l: 指定测试运行多长时间,单位:秒
-t: 运行模式,我们使用 TCP_CRR 来模拟 client 请求与 server 建连以后,由server 下发一定的数据量以后,关闭连接的这种 request/response 模式
-r: 分别指定 request 和 response 的字节数大小
默认配置Benchmark
记录下当前内核参数中与 tcp 相关的配置,并获取当前配置的 Benchmark 数据,用以在后续的优化中进行对比。
首先直接用 netperf 执行 20分钟的测试数据获取:
首先获取下当前测试流的关键帧的大小用以模拟尽量贴近实际业务场景的模拟:
# 首先 dump 到本地
ffmpeg -i http://xxxx/yyyyy/zzzzzzz.flv -c copy 1.flv
# 然后获取该片段的的首个关键帧的大小
ffmpeg -i 1.flv -frames:v 1 -f image2pipe -vcodec mjpeg - | wc -c
# 可以看到最后输出的为:117118,即 114KB 左右。
netperf 模拟 Player 请求下发直播数据,这里设置让 server 一次性下发 300KB 的数据,同时假设 Client 的 request 默认为 1KB, 测试 20分钟,命令如下:
测试数据:
$ ~$ netperf -H 127.0.0.1 -p 1234 -l 1200 -t TCP_CRR -- -r 1000,3000000
MIGRATED TCP Connect/Request/Response TEST from 0.0.0.0 (0.0.0.0) port 0 AF_INET to 127.0.0.1 () port 0 AF_INET : demo
Local /Remote
Socket Size Request Resp. Elapsed Trans.
Send Recv Size Size Time Rate
bytes Bytes bytes bytes secs. per sec
16384 131072 100 3000000 100.01 0.79
16384 131072
上述测试数据输出的
Local /Remote可以看到在下面多出一行,分别表示的是 local 和 remote 的 socket send and recv buffer’s bytes。 最后一列Trans表示的便是在测试的这段时间内平均每秒钟可以执行了多少次请求,即 0.79 次,相当于 Qps,越大说明效率越高。
TCP 内核参数优化:
内核参数配置
[root@XXXLink64 ~]# sysctl -a | grep "net\.ipv4\.tcp"
# 下面 4 个参数不区分协议
# 默认的 socket 接收窗口大小 (bytes)
net.core.rmem_default = 327680
# 最大的 socket 接收窗口大小 (bytes)
net.core.rmem_max = 327680
# 默认的 socket 发送窗口大小 (bytes)
net.core.wmem_default = 327680
# 最大的 socket 发送窗口大小 (bytes)
net.core.wmem_max = 3276800
# 在每个网络接口接收数据包的速率比内核处理这些包的速率快时,允许送到队列的数据包的最大数目,默认值是 1000
net.core.netdev_max_backlog = 3000
# 定义了系统中每一个端口最大的监听队列的长度,是个全局的参数
net.core.somaxconn = 2048
# 表示每个套接字所允许的最大缓冲区的大小
net.core.optmem_max = 81920
# 自动调整 tcp recv buffer
net.ipv4.tcp_moderate_rcvbuf = 1
net.ipv4.tcp_rmem = 131072 1048576 49152000
net.ipv4.tcp_wmem = 12288000 49152000 98304000
net.ipv4.udp_rmem_min = 4096
net.ipv4.udp_wmem_min = 4096
vm.lowmem_reserve_ratio = 256 256 32 0 0
# 用于控制当服务器的监听队列(listen 队列)溢出时,是否向客户端发送 TCP 重置(RST)信号以终止连接
net.ipv4.tcp_abort_on_overflow = 0
# 内核中与 TCP 窗口大小相关的一个参数,它影响接收窗口的大小调整行为
net.ipv4.tcp_adv_win_scale = 1
net.ipv4.tcp_allowed_congestion_control = reno cubic bbr
net.ipv4.tcp_app_win = 31
# 尽量合并包一起发送,减少发包数量。enable 了会增加延迟,建议关闭
net.ipv4.kcp_autocorking = 1
net.ipv4.tcp_available_congestion_control = reno cubic bbr
net.ipv4.tcp_available_ulp =
net.ipv4.tcp_base_mss = 1024
net.ipv4.tcp_challenge_ack_limit = 1000
net.ipv4.tcp_comp_sack_delay_ns = 1000000
net.ipv4.tcp_comp_sack_nr = 44
net.ipv4.tcp_congestion_control = bbr
net.ipv4.tcp_dsack = 1
net.ipv4.tcp_early_demux = 1
net.ipv4.tcp_early_retrans = 3
net.ipv4.tcp_ecn = 2
net.ipv4.tcp_ecn_fallback = 1
net.ipv4.tcp_fack = 0
net.ipv4.tcp_fastopen = 1
net.ipv4.tcp_fastopen_blackhole_timeout_sec = 3600
net.ipv4.tcp_fastopen_key = 5b1b3bb0-e9881f5a-8bf3fda0-1c410b36
net.ipv4.tcp_fin_timeout = 30
net.ipv4.tcp_frto = 2
net.ipv4.tcp_fwmark_accept = 0
net.ipv4.tcp_inherit_buffsize = 1
net.ipv4.tcp_init_cwnd = 15
net.ipv4.tcp_init_rto = 1000
net.ipv4.tcp_invalid_ratelimit = 500
# TCP发送keepalive探测消息的间隔时间(秒),用于确认TCP连接是否有效
net.ipv4.tcp_keepalive_time = 7200
# 探测消息未获得响应时,重发该消息的间隔时间(秒)
net.ipv4.tcp_keepalive_intvl = 75
# 在认定TCP连接失效之前,最多发送多少个keepalive探测消息
net.ipv4.tcp_keepalive_probes = 9
net.ipv4.tcp_l3mdev_accept = 0
net.ipv4.tcp_limit_output_bytes = 1048576
net.ipv4.tcp_loss_init_cwnd = 10
# 允许TCP/IP栈适应在高吞吐量情况下低延时的情况,这个选项应该禁用
net.ipv4.tcp_low_latency = 0
net.ipv4.tcp_max_orphans = 524288
net.ipv4.tcp_max_reordering = 300
net.ipv4.tcp_max_syn_backlog = 62144
net.ipv4.tcp_max_tw_buckets = 6000
net.ipv4.tcp_mem = 2621440 3932160 5242880
net.ipv4.tcp_min_rtt_wlen = 300
net.ipv4.tcp_min_snd_mss = 48
net.ipv4.tcp_min_tso_segs = 2
net.ipv4.tcp_moderate_rcvbuf = 1
net.ipv4.tcp_mtu_probe_floor = 48
net.ipv4.tcp_mtu_probing = 0
net.ipv4.tcp_no_metrics_save = 1
net.ipv4.tcp_notsent_lowat = 8388608
net.ipv4.tcp_orphan_retries = 0
net.ipv4.tcp_pacing_ca_ratio = 120
net.ipv4.tcp_pacing_ss_ratio = 200
net.ipv4.tcp_probe_interval = 600
net.ipv4.tcp_probe_threshold = 8
net.ipv4.tcp_proc_sched = 1
net.ipv4.tcp_recovery = 1
net.ipv4.tcp_reordering = 5
net.ipv4.tcp_retrans_collapse = 1
net.ipv4.tcp_retries1 = 5
net.ipv4.tcp_retries2 = 15
net.ipv4.tcp_rfc1337 = 0
net.ipv4.tcp_rmem = 131072 1048576 16384000
net.ipv4.tcp_rto_max = 120
net.ipv4.tcp_rto_min = 200
net.ipv4.tcp_rx_skb_cache = 0
net.ipv4.tcp_sack = 1
net.ipv4.tcp_slow_start_after_idle = 0
net.ipv4.tcp_stdurg = 0
net.ipv4.tcp_syn_retries = 2
net.ipv4.tcp_synack_retries = 2
net.ipv4.tcp_synack_rto_interval = 200
# 表示是否打开TCP同步标签(syncookie),内核必须打开了CONFIG_SYN_COOKIES项进行编译,同步标签可以防止一个套接字在有过多试图连接到达时引起过载
net.ipv4.tcp_syncookies = 1
net.ipv4.tcp_thin_linear_timeouts = 0
# TCP时间戳(会在TCP包头增加12个字节),以一种比重发超时更精确的方法(参考RFC 1323)来启用对RTT 的计算,为实现更好的性能应该启用这个选项
net.ipv4.tcp_timestamps = 1
net.ipv4.tcp_tso_win_divisor = 3
net.ipv4.tcp_tw_ignore_syn_tsval_zero = 1
# 表示是否允许将处于TIME-WAIT状态的socket(TIME-WAIT的端口)用于新的TCP连接
net.ipv4.tcp_tw_reuse = 1
# 对于本端断开的socket连接,TCP保持在FIN-WAIT-2状态的时间(秒)。对方可能会断开连接或一直不结束连接或不可预料的进程死亡
net.ipv4.tcp_fin_timeout = 30
# 能够更快地回收TIME-WAIT套接字
net.ipv4.tcp_tw_recycle = 1
net.ipv4.tcp_tw_timeout = 60
net.ipv4.tcp_tx_skb_cache = 0
net.ipv4.tcp_wan_timestamps = 0
net.ipv4.tcp_window_scaling = 1
net.ipv4.tcp_wmem = 4096000 16384000 32768000
net.ipv4.tcp_workaround_signed_windows = 0
优化内容
以下均为仅优化单边的 Server 测参数。
BBR
编辑 /etc/sysctl.conf,添加或修改如下参数:
# 设置 tcp 拥塞算法为 bbr
net.ipv4.tcp_congestion_control = bbr
使参数立即生效:
$ sysctl -p
测试结果
$ ~$ netperf -H 127.0.0.1 -p 1234 -l 300 -t TCP_CRR -- -r 1000,3000000
MIGRATED TCP Connect/Request/Response TEST from 0.0.0.0 (0.0.0.0) port 0 AF_INET to 127.0.0.1 () port 0 AF_INET : demo
Local /Remote
Socket Size Request Resp. Elapsed Trans.
Send Recv Size Size Time Rate
bytes Bytes bytes bytes secs. per sec
436600 87380 100 3000000 300.00 1.06
436600 87380
可以看到在开启了 bbr 拥塞算法后,Trans 由 0.79 升到了 1.06,有了明显的提升。
但是实际优化数据不会这么明显,因为线上环境我们只能开启 server 测的 bbr,而无法控制 client 同时开启。
SocketBuffer
$ sysctl -a | egrep "rmem|wmem|adv_win|moderate"
net.core.rmem_default = 327680
net.core.rmem_max = 327680
net.core.wmem_default = 327680
net.core.wmem_max = 3276800
net.ipv4.tcp_adv_win_scale = 1
net.ipv4.tcp_moderate_rcvbuf = 1
net.ipv4.tcp_rmem = 131072 1048576 49152000
net.ipv4.tcp_wmem = 12288000 49152000 98304000
net.ipv4.udp_rmem_min = 4096
net.ipv4.udp_wmem_min = 4096
vm.lowmem_reserve_ratio = 256 256 32 0 0
测试结果对比
- 上述默认配置,无调整 buffer
$ netperf -H 100.100.57.20 -p 1234 -l 600 -t TCP_CRR -- -r 1000,300000
MIGRATED TCP Connect/Request/Response TEST from (null) (0.0.0.0) port 0 AF_INET to (null) () port 0 AF_INET : demo
Local /Remote
Socket Size Request Resp. Elapsed Trans.
Send Recv Size Size Time Rate
bytes Bytes bytes bytes secs. per sec
131072 131072 1000 300000 599.99 1.59
16384000 1048576
- 强制64KB buffer
配置 net.ipv4.tcp_wmem 为 65536 后的测试结果 sysctl -w net.ipv4.tcp_wmem="65536 65536 65536" :
$ netperf -H 100.100.57.20 -p 1234 -l 600 -t TCP_CRR -- -r 1000,300000
MIGRATED TCP Connect/Request/Response TEST from (null) (0.0.0.0) port 0 AF_INET to (null) () port 0 AF_INET : demo
Local /Remote
Socket Size Request Resp. Elapsed Trans.
Send Recv Size Size Time Rate
bytes Bytes bytes bytes secs. per sec
131072 131072 1000 300000 599.99 1.16
65535 1048576
可以看到之前配置了 64KB 的 send buffer 后,Trans 由 1.59 下降到了 1.16,有明显的下降,但是上述配置是将 min、default、max 均全部强行配置为 64KB,失去了动态伸缩的能力,如果仅配置 default 为 64KB,不限制最大值,则不受影响。
tcp_fastopen
在上述配置中,tcp_fastopen 配置为 1,即仅开启 Client 的 fastopen,而未开启 server 测的 fastopen,不是最佳配置,需要调整为 3 同时开启 client 和 server 测的 fastopen。 tcp_fastopen 配置项说明:
tcp_fastopen - INTEGER
Enable TCP Fast Open (RFC7413) to send and accept data in the opening
SYN packet.
The client support is enabled by flag 0x1 (on by default). The client
then must use sendmsg() or sendto() with the MSG_FASTOPEN flag,
rather than connect() to send data in SYN.
The server support is enabled by flag 0x2 (off by default). Then
either enable for all listeners with another flag (0x400) or
enable individual listeners via TCP_FASTOPEN socket option with
the option value being the length of the syn-data backlog.
The values (bitmap) are
===== ======== ======================================================
0x1 (client) enables sending data in the opening SYN on the client.
0x2 (server) enables the server support, i.e., allowing data in
a SYN packet to be accepted and passed to the
application before 3-way handshake finishes.
0x4 (client) send data in the opening SYN regardless of cookie
availability and without a cookie option.
0x200 (server) accept data-in-SYN w/o any cookie option present.
0x400 (server) enable all listeners to support Fast Open by
default without explicit TCP_FASTOPEN socket option.
===== ======== ======================================================
结论
在目前环境中的内核配置中,对首开有明显影响的只有三个参数:
- 1、BBR 的拥塞算法;
- 2、TCP 的 send buffer 最大值要足够大;
- 3、开启 tcp_fastopen 需要开启 server 测,至少为 2。
路由优化记录
直播片源选用 3.4Mbps 的码率,播放器选择 ffplay 进行拉取,在发送端(直播服务器)通过 tcpdump 抓包,对比查看发送 1MB 数据所耗费的时间线,这里是局域网环境,所以 lastmile 的带宽不是瓶颈。
Tcp 的 initcwnd 默认值为 10,倘若设置过大会造成对网络的冲击,根据经验选择默认配置 10 与 40 两者之间进行对比。
环境准备
首先在发送端直播服务器上为指定网卡增加 100ms 的主动延迟,以放大数据影响,方便对比结果。
# 增加 100ms 的固定延迟
$ sudo tc qdisc change dev eno1 root netem delay 100ms
# ping 验证
$ ping 100.100.32.108
PING 100.100.32.108 (100.100.32.108) 56(84) bytes of data.
64 bytes from 100.100.32.108: icmp_seq=1 ttl=63 time=104 ms
64 bytes from 100.100.32.108: icmp_seq=2 ttl=63 time=103 ms
64 bytes from 100.100.32.108: icmp_seq=3 ttl=63 time=104 ms
64 bytes from 100.100.32.108: icmp_seq=4 ttl=63 time=103 ms
^C
--- 100.100.32.108 ping statistics ---
4 packets transmitted, 4 received, 0% packet loss, time 3003ms
rtt min/avg/max/mdev = 102.763/103.307/103.550/0.322 ms
Case1
未修改 tcp initcwnd 的测试场景。
- 在发送端(直播服务器)测抓包:
sudo tcpdump -i eno1 -s 1500 tcp and host 100.100.32.108 and port 8080 -w tcp_10cwnd_100msdelay.pcap - 在远端进行拉流(100.100.32.108):
拉取播放 10秒左右即可。
ffplay http://100.100.57.20:8080/ztest/A123.flv\?domain\=h3.xxx.com
- Wireshark 分析:
可以看到如下截图,接收 1 * 10^6 即1MB的数据时大约耗时在 900ms。
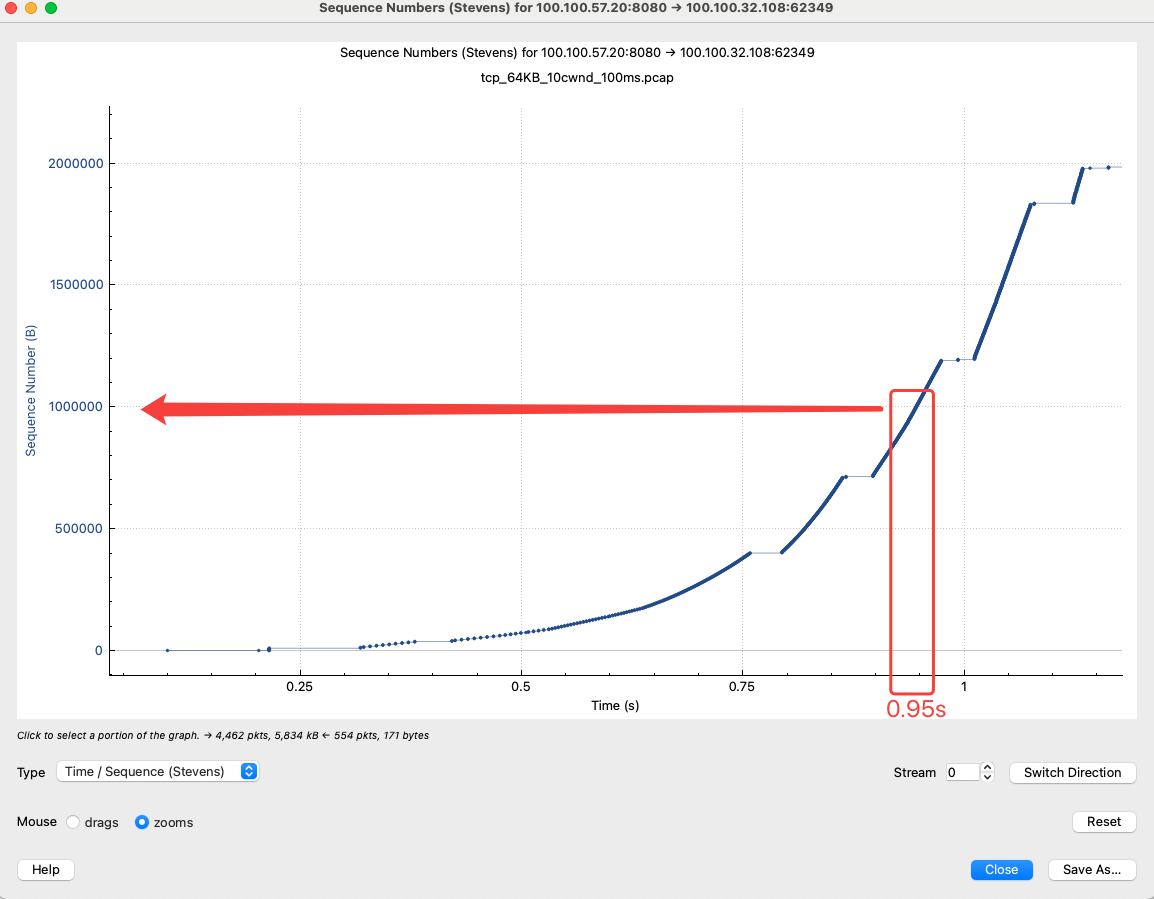
Case2
调整 initcwnd 为 40,通过 ip route 进行调整。
- 首先通过
sudo ip route show进行查看:
~$ sudo ip route show
default via 100.100.56.254 dev eno1 initcwnd 10
default via 100.100.56.254 dev eno1 proto static metric 100
default via 100.100.56.254 dev eno1 proto dhcp src 100.100.57.20 metric 100
100.100.56.0/23 dev eno1 proto static scope link initcwnd 10
100.100.56.0/23 dev eno1 proto kernel scope link src 100.100.57.20 metric 100
100.100.56.254 dev eno1 scope link initcwnd 10
172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1 linkdown
- 然后依次对各 route 进行配置:
sudo ip route change 100.100.56.254 dev eno1 scope link initcwnd 40
sudo ip route change via 100.100.56.254 dev eno1 initcwnd 40
sudo ip route change 100.100.56.0/23 dev eno1 proto static scope link initcwnd 40
- 配置后如下:
$ ~$ sudo ip route show
default via 100.100.56.254 dev eno1 initcwnd 40
default via 100.100.56.254 dev eno1 proto static metric 100
default via 100.100.56.254 dev eno1 proto dhcp src 100.100.57.20 metric 100
100.100.56.0/23 dev eno1 proto static scope link initcwnd 40
100.100.56.0/23 dev eno1 proto kernel scope link src 100.100.57.20 metric 100
100.100.56.254 dev eno1 scope link initcwnd 40
172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1 linkdown
- 在发送端(直播服务器)测抓包
sudo tcpdump -i eno1 -s 1500 tcp and host 100.100.32.108 and port 8080 -w tcp_40cwnd_100msdelay.pcap
- Wireshark 分析
可以看到 init cwnd 为 40 后,在 tcp 的慢启动状态发包变得很激进,接收端接收 1MB 的数据大约为 550ms,节省了大约 350ms,大约 3 个 rtt 的时间。
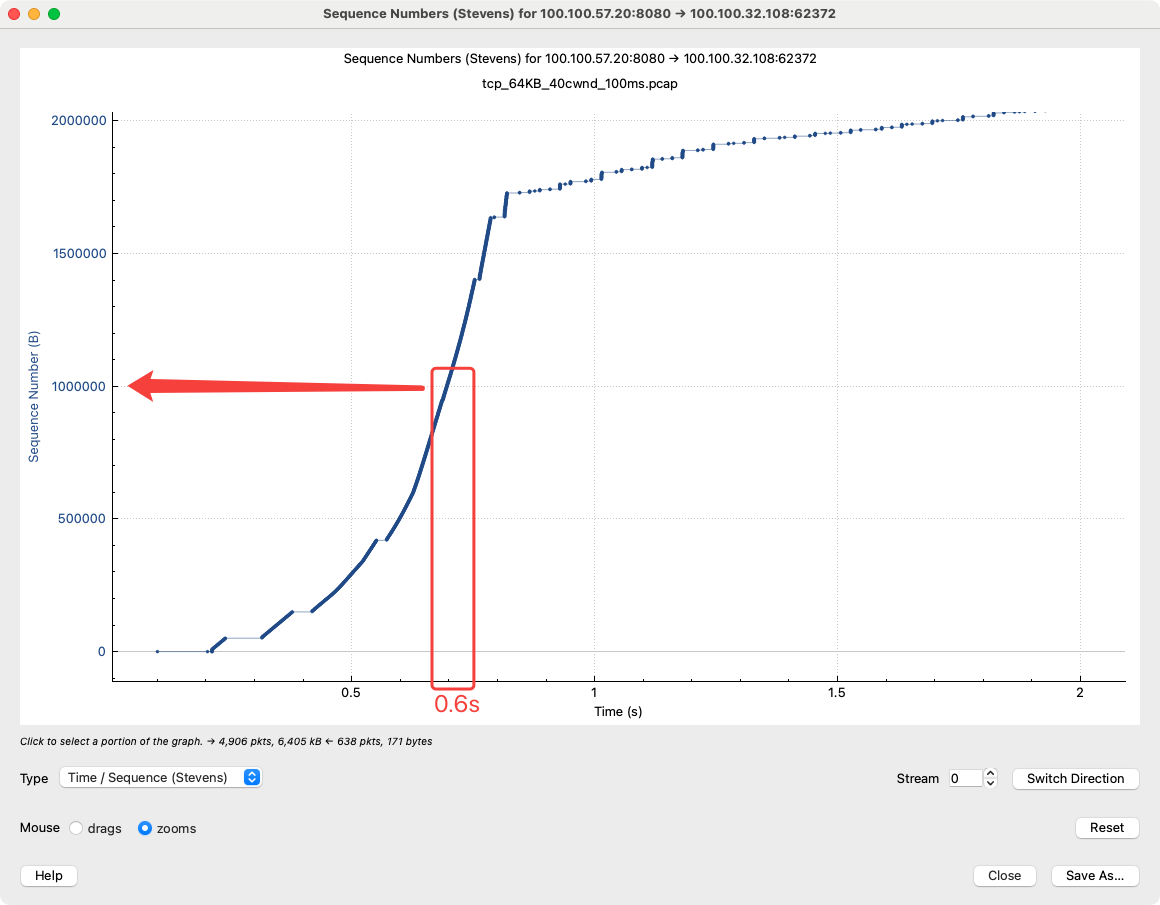
结论
如上,调整 INITCWND 为 40后,在秒开数据为 1MB 的场景中,大约可为秒开节省 3 个左右的 rtt 时间,下一步可以在线上进行初步的验证,可逐步放开该值为 20、30、40,在数据不断的优化的情况下降低调整风险,逐步实现优化。
版权声明: 如无特别声明,本文版权归 Mr Chen 所有,转载请注明本文链接。
(采用 CC BY-NC-SA 4.0 许可协议进行授权)
本文标题:《 直播场景TCP秒开优化 》
本文链接:https://gbcpp.github.io/notes/tcp-optimize-livestream-scene.html
本文最后一次更新为 天前,文章中的某些内容可能已过时!
技术工作者
